Introduction
The health of Queenslanders: Report of the Chief Health Officer Queensland was released for the first time in 2006. Past versions are available from the Queensland Government’s Publications Portal website. Over time, methodologies may change as new information becomes available or to align with methods used in other areas.
This page summarises the methods used in this release. For methods used in past editions, please see the archived versions in the Publication Portal above.
Terminology
Inclusive language
This report endeavours to use inclusive and appropriate language for all people throughout. Preferred terms are described below. Readers are encouraged to provide feedback for terms that are omitted or incorrect using the report Feedback form.
First Nations peoples
Queensland Health recognises and respects both Aboriginal peoples and Torres Strait Islander peoples, as the First Nations people in Queensland. Queensland Health’s preference is to use First Nations peoples and, in respect of both cultural groups, recognises Aboriginal and Torres Strait Islander peoples as acceptable terms. Queensland Health acknowledges that local environment and operating context will determine preferred choice. More information about Queensland Health’s preferred terminology is available from the Terminology guide for the use of ‘First Nations’ and ‘Aboriginal’ and ‘Torres Strait Islander’ references.
LGBTQIA+
LGBTQIA+ refers to people and families who identify as lesbian, gay, bisexual, transgender, queer, intersex or asexual. The ‘+’ reflects that the letters of the acronym do not capture the entire spectrum of sexual orientations, gender identities and intersex variations, and is not intended to be limiting or exclusive of certain groups.
Sex and gender
This report routinely reports health measures by biological sex (male and female). It is acknowledged that this does not capture important variations by gender and sexual orientation. Health assessment by gender and sexual orientation has typically been undertaken in specialist studies.
Recently, the Australian Bureau of Statistics (ABS) developed Standards for sex, gender, variations of sex characteristics and sexual orientation variables. These standards are anticipated to be increasingly used across health reporting systems. This will enable more routine reporting by gender and will increase comparability across data sources over time.
Because some health conditions are sex-specific but may be experienced by people who do not identify with that sex (for example, cervical screening), language that is not sex-specific was used in some report sections (for example, ‘cervical screening participants’ or ‘people with a cervix’).
Burden of disease reporting
Burden of disease is expressed as ‘years of healthy life lost’, ‘fatal burden’, ‘non-fatal burden’ or ‘disability burden’ to distinguish from more general use of the term ‘burden’ which is increasingly being used in other contexts.
The technical terms for reporting formal burden of disease measures are disability-adjusted life years (DALYs), years of life lost (YLL) and years lived with disability (YLD).
The Australian Burden of Disease (ABDS), the Global Burden of Disease (GBD), and the Queensland Burden of Disease studies are all used in this report. Because burden of disease studies use different methodologies, different studies should not be compared. Because the evidence base is continuously updated, burden of disease studies re-calculate results for previous years to enable appropriate comparisons.
Years and time periods
Periods of time are explicitly defined in the text and are inclusive of the entire period (for example, ‘from 2020 to 2022’ is inclusive of 2020, 2021 and 2022).
The following conventions are used to indicate the period of time used for results based on a:
- financial year yyyy–yy (‘2021–22’; financial year from 1 July 2021 to 30 June 2022)
- calendar year yyyy (‘2022’; calendar year from 1 January 2022 to 31 December 2022)
- combined number of calendar years yyyy–yyyy (‘2020–2022’; calendar years from 1 January 2020 to 31 December 2022)—also referred to as ‘pooled’ data.
Geographic areas
Remoteness areas
Remoteness is determined by Accessibility/Remoteness Index of Australia (ARIA+). Categories of the five categories of remoteness areas are combined for some measures to avoid data cells with small numbers; this information is included in figures footnotes where applicable.
Area-based socioeconomic status
‘Socioeconomic status’ is measured using the Socio-economic indexes for areas (SEIFA) and may be reported as Index of Relative Socio-economic Disadvantage (IRSD) or Index of Relative Socio-economic Advantage and Disadvantage (IRSAD), depending on primary source information.
Definitions of both SEIFA and Remoteness were sourced from the ABS. Both measures are updated following the Australian Census.
Other geographic boundaries
Other geographic boundaries used for reporting are described in the Our regions section.
Methodological information
This report uses numerous primary and secondary data sources to provide a comprehensive assessment of the health status of Queenslanders. Providing current methodological and other technical documentation is the responsibility of the relevant data custodians.
This report provides hyperlinks to the primary data source where technical information can be sourced. The hyperlink may appear in individual citations in the Reference section, in a footnote toa data dashboard or figure, or in the report’s Data sources table.
Data types
Underlying differences in data collection can require different statistical approaches. For instance, count data collected in administrative databases or registries (for example hospital episodes of care or notifiable condition counts) are analysed with different techniques than survey data (for example, the Queensland preventive health survey or the National Health Survey).
Because counts are an enumeration of events, statistical calculations on counts are typically more straightforward. Survey data, however, is collected from a sample of the population and requires additional manipulation to ensure that the estimates from the sample data is representative of the underlying
population. This is because survey contact and response rates may differ between subsets of the population, which can lead to biased results. Response rates commonly vary by age and sex, therefore, surveys are benchmarked to the age and sex distribution of the underlying population by generating sample weights. Sample weights are then applied in the majority of analyses, giving population-weighted estimates that are generalisable to the population of interest.
Statistical measures
Numerous statistical measures are used in this report. Results at a point in time, for example a calendar year, are typically reported as rates, counts, or prevalence. Rates may be crude rates, age-standardised rates (ASR), or age-specific rates. In text, ASRs are referred to as standardised rates. For survey data, calculations of these measures also includes applying the survey weight.
Prevalence
Reporting results as a prevalence is common for survey data including the Queensland preventive health survey (QPHS) and other population surveys used in this report. Survey results often apply survey weights and the prevalence is the population-weighted proportion of survey respondents with the characteristic of interest.
Rates
Age-standardised
Because many health conditions and behaviours are associated with age, comparing populations with different age structures means that health differences due to age may not easily be distinguished from other factors. To adjust for the effects of age and assess whether health differences are due to other factors, a statistical technique called age-standardisation is commonly used.
Because this report focuses on long term trends and presents results by geographic areas, adjusting for the effects of differences in age distributions is a priority. When available, age-standardised rates are therefore used.
Direct age-standardisation converts the crude overall rate estimate to the rate that would have occurred if the age structure was that of the standard population. In this report, the 2001 Australian population was used as the standard population, unless otherwise stated. ASRs calculated using different standard populations cannot be directly compared.
Crude rate
In some instances, crude rates may be more appropriate or be the only available information. Crude rates are calculated by dividing the total number of events by the total population, multiplied by a constant, such as 100,000, to give crude rate for 100,000 persons.
In some instances, both crude and age-standardised rates are included. For example, supplemental data under Additional information at the bottom of a page may include options to select crude rates and/or event count information.
Crude rates will differ from standardised rates, occasionally by a considerable degree. This is often caused by a large age effect due to over-representation of older age groups. Since age-standardisation adjusts for the age effect,
the differences in standardised rates between regions would be due to factors other than age.
Age-specific rates
Age-specific rates are limited to a particular age group. They are calculated by dividing the number of health events in the age group by the total number of target population in that age group, multiplied by a constant, such as 100,000, to give age-specific rate for 100,000 persons.
Rankings
Queensland or Australia are often compared with other jurisdictions, using ranks. To apply ranks, the health event is ordered from best (ranked first) to worst (ranked last). A ranking of 1 consistently indicates the jurisdiction with the best outcome. Lower ranks indicate progressively worse health outcomes relative the higher ranked jurisdictions.
Ranks do not imply a statistical difference, however. It is common for health outcomes for groups, such as states and territories, to be so closely similar that there is no statistically significant difference. See additional information under Interpreting statistics.
Interpreting statistics
Statistical significance
Statistical significance helps quantify whether a result is likely due to chance or to some factor of interest. Results that are statistically significant are reported in the text. Results that do not reach statistical significance, or are missing a measure of statistical significance, are omitted or reported as similar or that there is no evidence of a difference. Some results have large margins of error and despite seemingly large percentage point differences, there will be no corresponding statistical significance.
A confidence interval (CI) is a range of values that is expected to contain the true population value for the majority of times data are collected on multiple samples, typically 95% of the time. Thus, a large interval reflects less certainty in the precision of the estimate. A conservative approach to assessing statistical difference is to compare CIs. When CIs do not overlap, the differences are unlikely to be due to chance. Comparison of CIs is a conservative approach, and is the predominant method to assessing statistical significance due to the large number of comparisons that occur across this report.
The relative standard error (RSE) is calculated by dividing the standard error of the estimate by the estimate itself and is expressed as a percentage. It is particularly useful when assessing the reliability of estimates with large CIs. Estimates with an RSE less than 25% are reliable and are reported. Estimates with an RSE between 25% and 50% should be interpreted with caution. Estimates with an RSE greater than 50% are not considered sufficiently reliable and are not reported.
Reporting statistical difference
Differences between results are reported as a percentage increase/decrease, higher/lower or ‘times higher’.
The percentage difference is calculated as the difference between the reference rate and comparison rate divided by the reference rate. For example, the injury hospitalisation rate was 73.9% higher in remote and very remote areas than major cities. The rate for Major cities is the reference rate and remote and very remote areas is the comparison rate since you are comparing remote and very remote areas to major cities (6,344.9 and 3,647.7 per 100,000 persons, respectively). The percentage difference will therefore be (6,344.9-3,647.7) / 6,344.9 = 0.739 (or 73.9%). Since this result is positive it can be described as “percent higher” whereas if it were a negative result, it would be “percent lower”.
For percentage differences greater than 100% it may be better to describe the difference in terms of ‘times higher’ noting that 100% higher is 2 times higher (or doubled) and 200% higher is 3 times higher. For example, injury mortality was 2.8 times higher in males than females (57.1 and 20.7 per 100,000 persons, respectively). The percentage difference is (57.1-20.7) / 20.7 = 1.758 (176% or rounded to 180%) this then can be described as 2.8 times higher. These calculations are typically applied only when the results for the compared groups are significantly different. In a limited number of cases, this approach may be used for more general descriptive purposes.
Percentage point differences are uncommon in this report. A percentage point difference is the difference between two estimates. If the prevalence in group 1 is 30% and in group 2 is 34%, the percentage point difference is 4-percentage points.
Trend analysis
High level trends, with a focus on Queensland, are reported. National trends, when included, provide context or highlight differences to Queensland trends. It is acknowledged that these results may differ from more detailed trend analyses that includes factors explaining the variability. In this report, the intent is to demonstrate differences in trends across health conditions using a consistent analytical approach. To control for the ageing of the population, standardised rates were used.
Caution should be used in comparing data over time as there have been changes in coding standards and between the International Statistical Classification of Diseases and Related Health Problems, Australian Modification (ICD-10-AM) editions. For example: the coding standard for viral hepatitis in the 8th edition of ICD-10-AM introduced in 2013–14 may account for a proportion of the increase in the rate of vaccine preventable conditions. See Appendix A - Admitted patient care 2013–14: Australian hospital statistics, AIHW, for more details.
In cases where there was a clear underlying data coding change, the trend may be described starting with the data point following the coding change. For example, changes to ICD-10-AM hospital episode coding for many chronic conditions changed in 2015–16 which is why trend analysis for chronic conditions was conducted for 2015–16 onwards.
Changes may also occur to ICD-10-AM code groups used to define some health conditions. This has occurred between the 2023 and 2025 release of this report and more information is available on the Data definitions page under About this report. This was to better align with definitions used in other jurisdictional or national reporting systems and increase comparability. These definitional changes were applied across the entire reported time series where possible.
Statistical trends analysis
This report uses several approaches to reporting trends.
Trends results from the QPHS are based on prevalence reported primarily in the Our lifestyle chapter. The Poisson method is used for two main reasons:
- In the underlying data unit record data, information including population weights is available, which is required for this method.
- As these are survey estimates from a sample, precision of these estimates needs to be considered in the trend calculation as opposed to administrative type data where these are not subject to sampling variation.
The log linear regression method is used elsewhere as it is a simpler method that does not require full access to unit record data and creates the same output measure to describe the trend which is the annual percentage change (APC).
Poisson method
The Poisson method for trend in the QPHS first calculates annual prevalence estimates and standard errors for the relevant indicators using Stata svy: commands to account for the complex sampling design. The prevalence estimate and standard error are used to calculate an equivalent numerator and denominator by using the following formula:
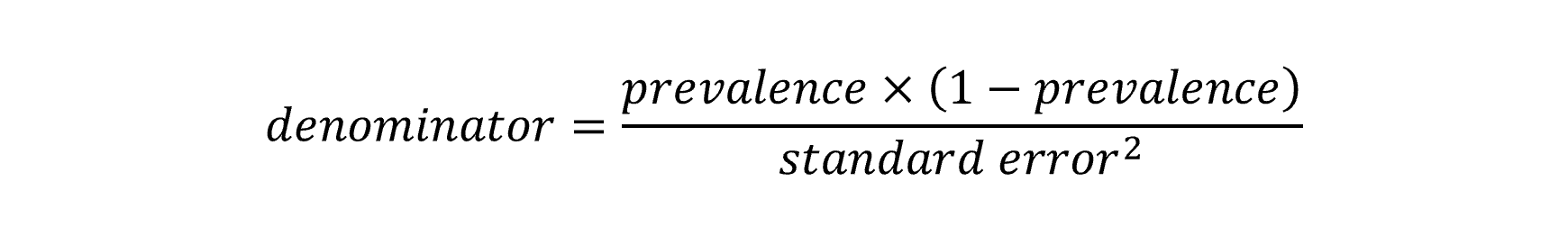
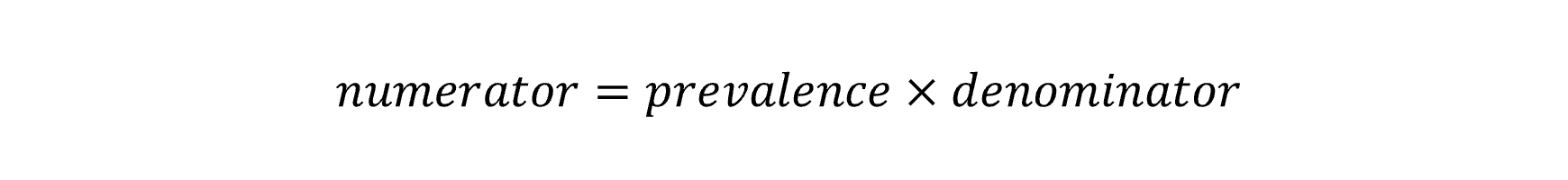
These terms are used in Poisson regression with year as the predictor variable, the numerator as the outcome count parameter and the denominator as the exposure. The resulting model co-efficient for year and its confidence intervals are exponentiated to calculate the APC for the time period. A test for curvature (or non-linearity) can be made by including the square of the year into the model. If this co-efficient is statistically significant it would suggest that the trend is not consistent across the time period and can be described with two linear trends over that period.
More information is available in the report Trends in preventive health risk factors 2002–2013 (Appendix 1).
Log linear method
This method is used for trend analysis for indicators that are not from survey data. It has the advantage of not requiring access to the underlying unit record data, and is particularly useful for administrative data and data from outside Queensland Health such as AIHW and ABS. With this method the natural log of the outcome rate or percentage is taken for each year of data. Next, a linear regression is run over the data with year being the predictor and the log of the rate being the outcome. As with the Poisson regression method above, exponentiating the model co-efficient for year will result in the APC. Again, as with the Poisson method, a test for curvature (or non-linearity) can be made by including the square of the year into the model. If this co-efficient is statistically significant, it suggests the trend is not consistent across the time period. A Davies test was performed to determine which is the most likely year where the trend changed (the breakpoint). The non-linearity can then be described by two linear trends before and after the breakpoint. In the 2025 release of the CHO report, breakpoints were limited to one across the time series.
Analyses using this approach are typically used for age-standardised rates. In figures, quadratic models are plotted on a standard y-axis which may cause some distortion to trend lines. Hover text includes additional information such as the APC and whether results were statistically significant (noted by ’*‘) or not significant (NS). Trend results in the Our lifestyle section, have ’no significant change’ in figure hover boxes. For all trend figures, the APC and 95% CIs are reported and significance be assessed directly by whether the CIs include 0.
For both the Poisson and log linear method, results are reported across the applicable time period using the following equation:
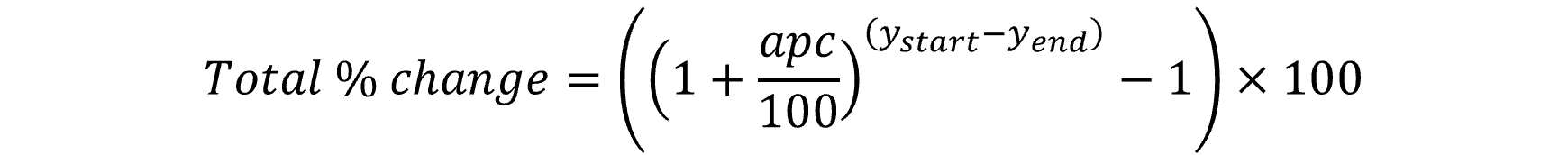
Descriptive trend assessments
Trends may be descriptively reported when statistical trend analysis was not feasible. Typically, the change is described as the difference between the first and last data point of the series. A similar approach was used where a change in trend was visible but could not be attributed to a change in coding practices.